- My Forums
- Tiger Rant
- LSU Recruiting
- SEC Rant
- Saints Talk
- Pelicans Talk
- More Sports Board
- Fantasy Sports
- Golf Board
- Soccer Board
- O-T Lounge
- Tech Board
- Home/Garden Board
- Outdoor Board
- Health/Fitness Board
- Movie/TV Board
- Book Board
- Music Board
- Political Talk
- Money Talk
- Fark Board
- Gaming Board
- Travel Board
- Food/Drink Board
- Ticket Exchange
- TD Help Board
Customize My Forums- View All Forums
- Show Left Links
- Topic Sort Options
- Trending Topics
- Recent Topics
- Active Topics
Started By
Message
re: Nate trying to get his mojo back
Posted on 4/24/17 at 3:29 pm to therick711
Posted on 4/24/17 at 3:29 pm to therick711
quote:No from a bayesian perspective, you can conclude that a model with 1% chance had an incorrect apriori probability assumption.
Now we're getting down to it. All of the models were presumptively correct because they all gave Trump a chance at winning. Good deal.
I'm not arguing that he was correct, but I'm arguing that given the data, it was asinine to conclude Trump had a >50% chance because all of the data suggested he was behind.
On the flip side, it was also asinine to conclude he had a chance close to 0% since we know polling errors of a couple percent occur fairly frequently.
So based on the available data, and the historical data of polling errors, his model was about as sound as it comes given this--although I'm not discounting that it was flawed. Silver himself has acknowledged that the Selzer Iowa poll (Selzer is one of the top pollster), should have implied Wisconsin (neighboring state) was closer than the other polls suggested.
But in the end, these types of outlying events help improve the procedures for the next time.
This post was edited on 4/24/17 at 3:31 pm
 1
1

Posted on 4/24/17 at 3:38 pm to buckeye_vol
quote:
I'm not arguing that he was correct, but I'm arguing that given the data, it was asinine to conclude Trump had a >50% chance because all of the data suggested he was behind.
You are arguing with yourself, then.
You cannot simultaneously laud his model for being more near 50/50 and state that you have no idea what the a priori probability was. Your argument truly boils down to the fact that any poll that gave him a greater than 0 chance of winning was correct because you don't know what the true probability is. The same reasoning that applies to Silver applies just as meaninglessly to all greater than zero predictions. That reasoning just happens to serve your position that Silver was least wrong.
Posted on 4/24/17 at 3:46 pm to therick711
quote:But based on the data, and the historical errors, we can make a reasonable inference that it wasn't close to 0 nor 50. So then 28% is about as close to a reasonable prediction as anybody had.
You cannot simultaneously laud his model for being more near 50/50 and state that you have no idea what the a priori probability was.
quote:No I'm not. Even with an unknown unknown apririo we can use some bayesian logic to conclude that 1% was not reasonable. Maybe it was closer to something closer to 40%, but 28% is the mot reasonable model available.
our argument truly boils down to the fact that any poll that gave him a greater than 0 chance of winning was correct because you don't know what the true probability is
quote:But that applies to just about any prediction. We are trying to conclude the most reasonable possibility.
That reasoning just happens to serve your position that Silver was least wrong.
But with Silver, he at least provides, not only the probability, he provides the margin for each outcome. We can judge his accuracy based on that, and unfortunately, I don't think many of the other predictions, other than NYT attempted to do that.
Posted on 4/24/17 at 3:49 pm to buckeye_vol
quote:
No I'm not. Even with an unknown unknown apririo we can use some bayesian logic to conclude that 1% was not reasonable. Maybe it was closer to something closer to 40%, but 28% is the mot reasonable model available.
Plenty of models had between 8-20%. You picking the Huffpos of the world shows how weak your position is.
You are using the same ex post facto logic that you are banging on people for using to criticize Silver. Just because his probability was closer to 50/50 doesn't mean he was the least wrong. Since your position is that this is all an exercise in math, we need to know what the true probability is to determine whether Silver's model was worth a shite.
This post was edited on 4/24/17 at 3:52 pm
Posted on 4/24/17 at 3:53 pm to therick711
quote:
Plenty of models had between 15-20%. You picking the Huffpos of the world shows how weak your position is.
quote:Feel free to add some, but of the 8 other models which have a prediction, only 2 had it between 15-20 percent, and 4 had them, with under 10%, with 3 under 2%.
FiveThirtyEight — “polls-only” and “polls-plus” (29% and 28%, respectively)
PollSavvy — a “16 y/o high school junior and his stats teacher” (18%)
The New York Times / The Upshot (15%)
PredictWise (11%)
Kremp / Slate (10%)
Daily Kos (8%)
The Huffington Post (1.7%)
DeSart and Holbrook (1.4%)
The Princeton Election Consortium (1%)
The average of those 8 models was 8.3%.
Posted on 4/24/17 at 3:54 pm to buckeye_vol
had the wrong number in my original post. I see three models give <2% which is what you're going off on.
This post was edited on 4/24/17 at 3:55 pm
Posted on 4/24/17 at 3:56 pm to therick711
quote:Those 3 models are clearly worse. Frankly I would argue that only the NYT and that high school kid were the only 2 that could be in consideration.
had the wrong number in my original post. I see three models give <2% which is what you're going off on.
Actually, that article that was linked earlier does a good job trying to quantify the most accurate modeler for the presidential election.
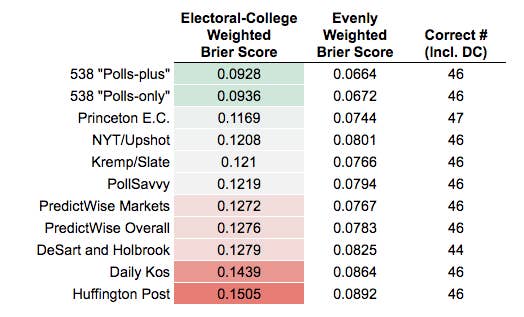
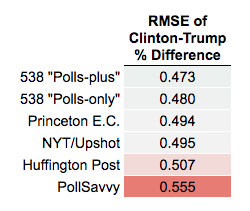
As well as the senate races.

quote:
Among the first group, FiveThirtyEight scored best (smaller numbers are better):
This post was edited on 4/24/17 at 4:16 pm
Posted on 4/24/17 at 4:00 pm to buckeye_vol
quote:
Those 3 models are clearly worse. Frankly I would argue that only the NYT and that high school kid were the only 2 that could be in consideration.
You don't know the true probability, so your supposition would just be based on the fact that it wasn't as close to giving Trump 50%, which is what you said we shouldn't do.
This post was edited on 4/24/17 at 6:01 pm
Posted on 4/24/17 at 4:02 pm to therick711
quote:I updated my post above, but 538 had the lowest predictive error in the 50 state elections.
You don't know the true probability, so your supposition would just be based on the fact that it wasn't as close to to giving Trump 50%, which is what you said we shouldn't do.
So you're right, determining the correct probability is probably a pointless endeavor, but looking at the predictive results, compared to the finals results, can at least give us a better idea.
This post was edited on 4/24/17 at 4:03 pm
Posted on 4/24/17 at 4:49 pm to League Champs
quote:By the way, your criticism becomes more ridiculous since Huffpo wrote an article about how they got it wrong.
Evidence: HuffPo and NyMag (using the exact same numbers) accused Nate of using 'trending data', rather than actual poll data. Nate admitted that he did. I gave you the NC example, that Nate readily admitted to
Why HuffPost’s Presidential Forecast Didn’t See A Donald Trump Win Coming
This tidbit seems pertinent:
quote:
Silver was right to question uncertainty levels, and was absolutely correct about the possibility of systematic polling errors--all in the same direction. Clearly, we disagree on how to construct a model, but he was right to sound the alarm.
This post was edited on 4/24/17 at 4:50 pm
Posted on 4/24/17 at 5:15 pm to buckeye_vol
quote:
By the way, your criticism becomes more ridiculous since Huffpo wrote an article about how they got it wrong.
Why HuffPost’s Presidential Forecast Didn’t See A Donald Trump Win Coming
This is why I am going to start ignoring you. theRick says the same thing about you. You use a point to prove your point, after you tell others not to use that point
So I'm not going to point out for others to read, that you have spent the last few pages condemning my use of NyMag's agreement with HuffPo logic, by using a HuffPo article to make that point. So, instead of pointing out that if their logic was wrong then (according to you), then how can I now rely on their logic being correct (according to you)?
Posted on 4/24/17 at 5:36 pm to League Champs
quote:Because you're using a journalist's (not those created the model) argument BEFORE the election, when they thought their model was right and Silver's was incorrectly giving him a better chance.
So I'm not going to point out for others to read, that you have spent the last few pages condemning my use of NyMag's agreement with HuffPo logic, by using a HuffPo article to make that point. So, instead of pointing out that if their logic was wrong then (according to you), then how can I now rely on their logic being correct (according to you)?
The article I linked was from their polling editor, whose focus is on polling methodology and statistics. She is involved in the actual nuts and bolts.
In addition, my article was from AFTER the election, and as you can see from the tables a few posts up, AFTER they were shown to be the WORST FORECASTER.
So you don't see the difference in the two articles that's fine; feel free to dismiss them both.
But you can't dismiss the evidence from a few posts above which shows Silver's models were the most accurate. You can say that's not "good enough," and I would agree. BUT your argument that he went beyond the model, and subjectively inflated it, has absolutely no support, and is especially ridiculous when you consider it was the MOST ACCURATE.
So how are you going to take such a ridiculous stance with no evidence to support it, and with plenty evidence against it?

 Page 8 of 8
Page 8 of 8


Popular
Back to top